

In this blog we will be working in our environment to implement splunk search head cluster configuration, keep following the steps to add new index in a cluster.
What is a cluster?
A computer cluster consists of a set of loosely or tightly connected computers that work together so that, in many respects, they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software.
What is search head cluster in splunk?
A search head cluster is a group of Splunk Enterprise search heads that serves as a central resource for searching. You can run or access the same searches, dashboards, knowledge objects, and so on, from any member of the cluster. To achieve this interchangeability, the search heads in the cluster share configurations, apps, search artifacts, and job loads.
Basically search head cluster is combination of two or more search heads which have exactly same configuration and are identical. In case of any one search head goes down other provides the service providing high availability
Why to use search head cluster? |Benefits of search head cluster?
Search head clusters provide these key benefits:-
Horizontal scaling – As the number of users and the search load increases, you can add new search heads to the cluster. By combining a search head cluster with a third-party load balancer placed between users and the cluster, the topology can be transparent to the users.
High availability – If a search head goes down, you can run the same set of searches and access the same set of search results from any other search head in the cluster.
No single point of failure –The search head cluster uses a dynamic captain to manage the cluster. If the captain goes down, another member automatically takes over management of the cluster
Components of search head cluster:-
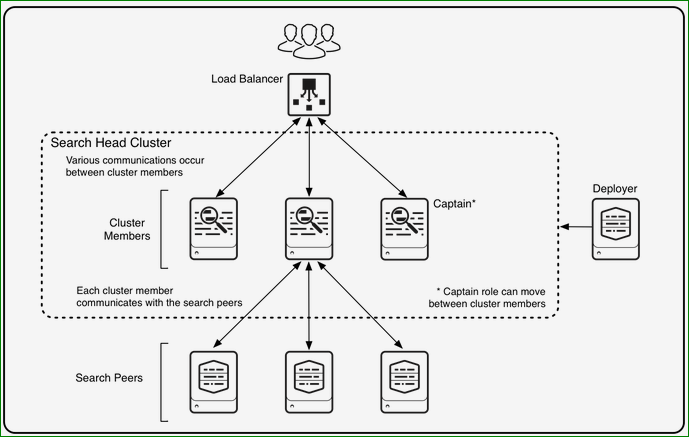
The deployer –This is a Splunk Enterprise instance that distributes apps and other configurations to the cluster members. It stands outside the cluster and cannot run on the same instance as a cluster member. It can, however, under some circumstances, reside on the same instance as other Splunk Enterprise components, such as a deployment server or an indexer cluster master node
Search peers – These are the indexers that cluster members run their searches across. The search peers can be either independent indexers or nodes in an indexer cluster.
Load balancer – This is third-party software or hardware optionally residing between the users and the cluster members. With a load balancer in place, users can access the set of search heads through a single interface, without needing to specify a particular one.
These ports must be available on each member:
- The management port (by default, 8089) must be available to all other members.
- The http port (by default, 8000) must be available to any browsers accessing data from the -member.
- The KV store port (by default, 8191) must be available to all other members. You can use the CLI commandsplunk show kvstore-port to identify the port number.
The replication port must be available to all other members
Implement search head cluster
- Determine cluster size.
- Make sure all insatance to be included in cluster should have same OS and version.
- Install splunk 8.0.5 package to all instances.
- Determine replication factor and port.
- Determine cluster will work along standalone indexer / or indexer cluster.
Requirements –
1) Deployer
2) Search Head Instances……(Sh-instance1, SH-instance2, SH-instance3)
IMPORTANT :
replication_factor – It states that how many SH replication copies we need if we have 3 Sh instances and want to replicate 3 copies then -replication_factor is 3 if more instances then we can set more replication factor
replication_port – we can define any port lets keep 9000
mgmt_uri – Own instance host ip address
conf_deploy_fetch_url – Deployer host ip address
1) To initialize Deployer in Deployer Instance edit server.conf file and set configurations.
→ vi /opt/splunk/etc/system/local/server.conf
[shclustering]
pass4SymmKey =
shcluster_label = cluster

2) Next in Search Head instances which we want to add those to SH-clustering, configure them.
→ /opt/splunk/bin/splunk init shcluster-config -mgmt_uri https://<your_site>::8089 – replication_port -replication_factor 3 -conf_deploy_fetch_url https://<your_site>::8089 -secret -shcluster_label
Then restart the splunk

→/opt/splunk/bin/splunk restart
Here is the /opt/splunk/etc/system/local/server.conf file which get configured

Pass4SymmKey genrally get decrypted
This will configure SH instances in Sh-Clustering mode we can check that by Logging in web console in Settings overall layout would be changed then → Settings → Search head clustering
3) It will not show anything until Search head captain is elected.
4) For electing captain go any of the SH instance which we want to set as captain In that SH-instance.
→ /opt/splunk/bin/splunk bootstrap shcluster-captain -servers_list “https://<your_site>:8089,https://<your_site>::8089,https://<your_site>::8089”

Then restart the splunk
→/opt/splunk/bin/splunk restart
Servers list are the Search head instances that comes under captain, it manages the sh-cluster
By replicating dashboards, reports, alerts, saved searches, created users.
Server list also include its own ip_host too.
4) To check Sh clustering is success all search head added to cluster or not Check on any instance
→ /opt/splunk/bin/splunk show shcluster-status
5) Apply Bundle through Deployer:-
• To apply Bundle to search head cluster member, run this command on deployer:-
→ /opt/splunk/bin/splunk apply shcluster-bundle -target https://<your_site>::8089
If you are still facing issue regarding splunk search head cluster configuration topic Feel free to Ask Doubts in the Comment Box Below and Don’t Forget to Follow us on 👍 Social Networks, happy Splunking >😉




{kind=link}