

In this blog we are going to onboard data using onboarding technique of data onboarding using python script in splunk.
What is need of onboarding data using scripts?
Imagine we have a web application where the REST API is been used to get data from databases. So we can access data from database using API’s.
API is been widely used in any of the application to communicate between backend and frontend. To onboard that data in splunk using API we have scripts input. Where we write a python script to get data from API’s validate it, arrange in proper format and send to splunk in form of JSON objects.
Using of the script inputs in splunk we can allow the script to run in using set cron schedule.
Example:- If script is been set in splunk app. We set a cron schedule of every 1 hour . so that specific python script will run it executes the commands written in python code. Calls data from the API and indexed in splunk.
Drawback of python script:-
Data Redundancy – When a python script run it gets data from API where API has old data as well as new data. When script is run it gets the data and ingest in splunk. There is a cause of Data Duplication which is not good practice of ingesting data in splunk.
Solved Drawback:-
The Data Redundancy caused is been resolved using a method called Checkpointing. Which is further explained below in working of script.
Working of scripts input
1 – Create a script file in app which you want to monitor script input it can be in any app (Search & Reporting or any newly created app).

Here is the location where you can create script file

app.py python file is created write program for getting data from API.
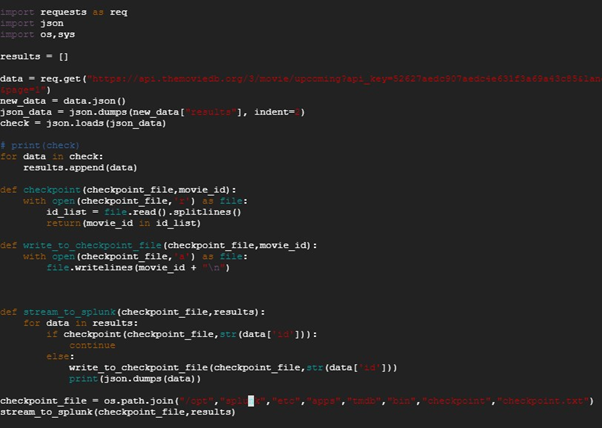
By vi editor app.py python file is created for getting data from API.
Create it and save it and restart the splunk by /opt/splunk/bin/splunk restart
Points to remember:-
When python script run for getting data and indexing in splunk interval is set e.g for 60 seconds then script will run for every 60 seconds which leads to same data will get indexed in splunk which leads to data redundancy.
For solving this we can do Checkpointing
Checkpointing is when data get called and indexed in splunk we can create a directory and a checkpoint.txt file
Create a checkpoint directory:-
/opt/splunk/etc/apps/search/bin/mkdir checkpoint
/opt/splunk/etc/apps/search/bin/cd checkpoint
Create a checkpoint.txt fie in that directory:-
/opt/splunk/etc/apps/search/bin/checkpoint/touch checkpoint.txt
When script will run for the first time from that data which is in list format they contains array from that particular array of data we save unique values from each data to checkpoint.txt file
Example:- In our data we have id value which is unique in every object of data we save that id values in checkpoint.txt file when script will run again in 60 seconds interval of time when it has same data which is already been indexed it will check id value of that data from checkpoint.txt file when id value match with new data id value it will skip that data and only indexed the data which are not indexed this will solve the issue of data redundancy.
Checkpointing is set in the same python script
2 – Go to Splunk web console
Setting → Data Inputs → select scripts

Create a new local script

Select script path which is etc/apps/search/bin or any app you created
Select script name which is script file you created where your python program resides
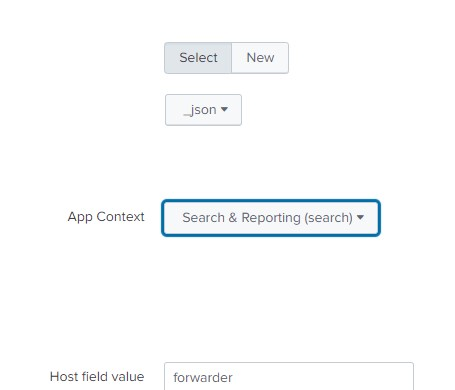
Here it is app.py select interval for at what time interval your script will run for getting new data e.g 60 seconds

Select sourcetype _json format, select app context in which app you added your script here it is Search & Reporting, select index to default or any index you previously created review file and submit it and start searching.
Search for :
index=”main” sourcetype=”_json”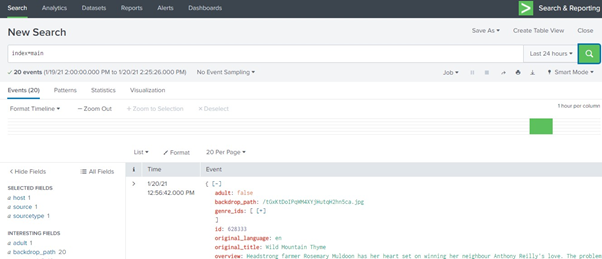
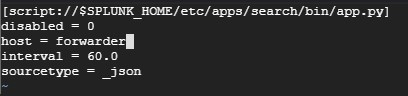
In inputs.conf script input is generated.
If you are still facing issue regarding data onboarding using python script Feel free to Ask Doubts in the Comment Box Below and Don’t Forget to Follow us on 👍 Social Networks, happy Splunking >😉





{kind=link}