

in this blog we are going to explain the basic operators of regular expressions. Splunk supports PCRE(Perl compatible regular expression).
What is a regular expression ?
It is basically a pattern matching programming language. The basic concept behind regular expression is to find a pattern from the text we have.
In splunk it is basically used for 3 different purposes
1) To extract a new field or create a new field
2) It can be used to filter out different events based on regular expression
3) To create a new field page
Here we are using Regular expressions 101 to test our regular expression
The link is: https://regex101.com/
We will discuss the common regular expression which can be used to filter out data
1.Regular expressions Basics
Some of the basic commands to match the regular expression are expressed here
(1) . : It matches any character except a new line. It can be always used as a wildcard character
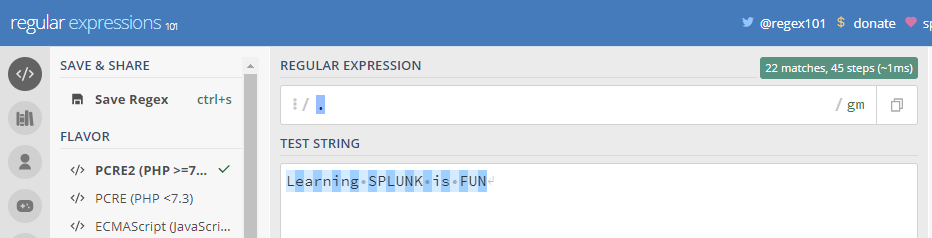
As you can see in the above example by providing the ‘.’ it matches the entire test string
(2) The string ab and a|b:
ab : It matches the string provided such as ab or any other string which required to be matched for eg
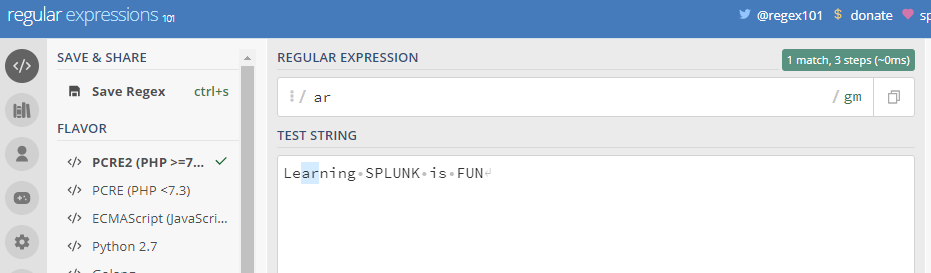
As you can see the string ar provided in the above expression matches in the test string
a|b : It matches any or both of the above character when it is found in the string

(3) \ : Also known as Escape character -It is used to escape any special character that may be used in string
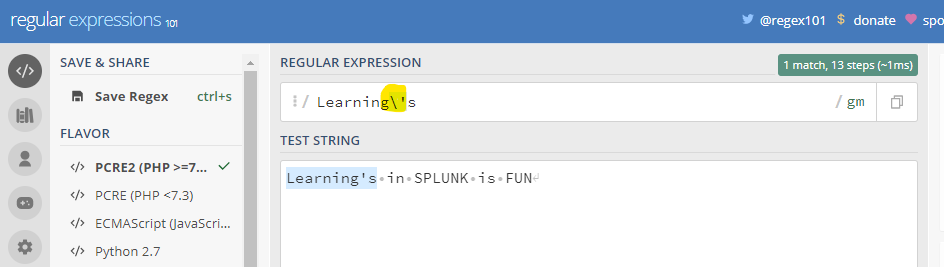
2.Quantifiers in Regular expressions
The quantifiers in regular expressions specifies how many instances of a character , group, or character class must be present in the input for a match to be found. The following are the important quantifiers which are essential are discussed
(1) * : The character matches 0,1 or more of the previous character which are specified
In the regular expressions
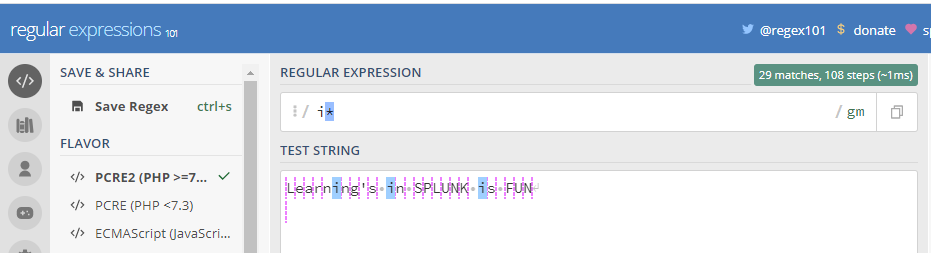
As you can see in the above example ( i* ) matches every i character in the test string when provided with the quantifier (*)
(2) + : This character when used matches 1 or more of the previous character when used in the regular expression
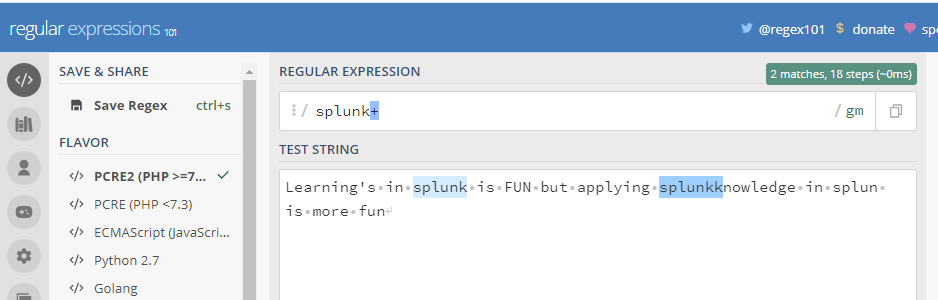
From the above eg it can be seen that it matches with splunk , splunk+ but not with splun as given in the test string.
(3) ? : This character matches exactly 0 or 1 occurrence of the previous character when specified in the regular expression
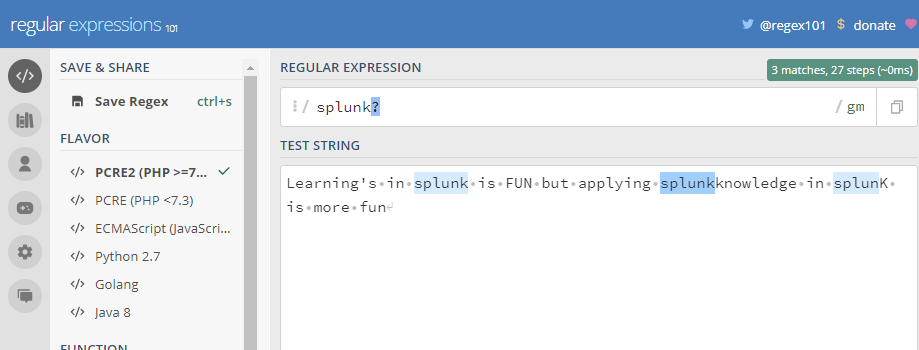
Quantifiers are usually greedy .The character (*) and (+) specified above causes the regular expressions engine to match as many occurrences .Appending the (?) character to a quantifier makes it lazy, it causes the regular expression engine to match as few occurrences as possible
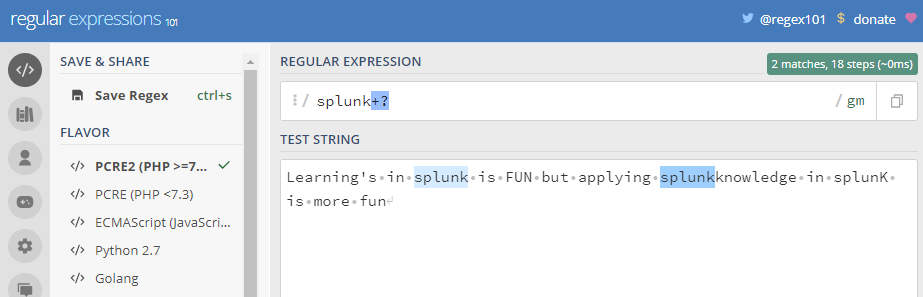
Here it matches the previous token(splunk) between 0 and 1 times, as many times as possible thus giving us greedy match.
Here with the above quantifier (?) when placed after the token matches between one and unlimited times , as few times as possible, expanding as needed thus giving us lazy match.
(4) {n} ,{n,} and {n,m} :This expression matches the specified expression with specified no of times/occurrences as provided in the flower brackets{}.
{n} : It matches exactly n times the previous character in the regular expression.

It can be seen that the splunk token is matched 1 time in every instance where it is occurring.
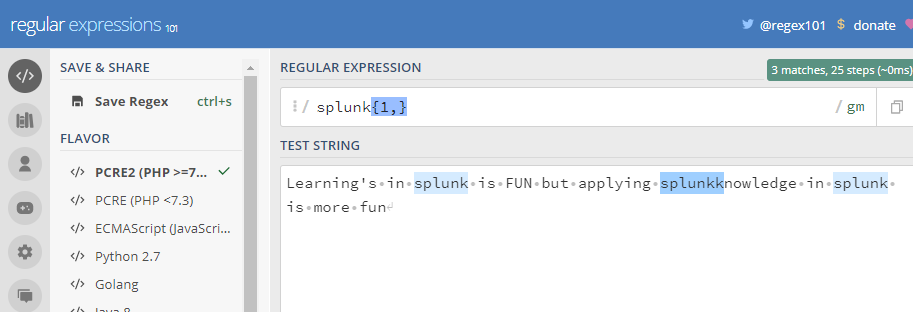
{n,} : It matches at least n times with the previous character in the regular expression
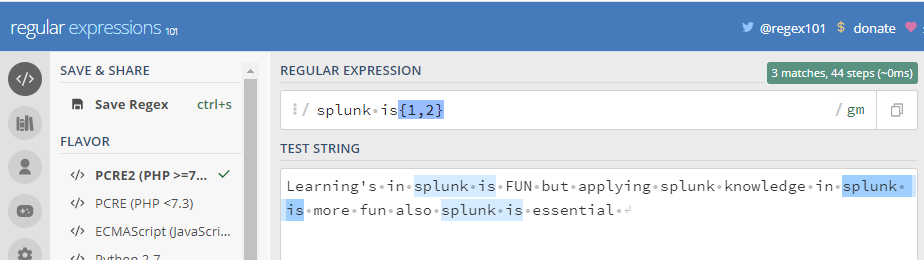
{n,m} : It matches from n to m times with the previous characters in the regular expression.
It can be seen that it matches the previous token between 1 and 2 times to as many times as possible in the given string.
3.Regular Expression Groups
Groups play an important role in regular expression .In splunk it plays a vital role because if you want to extract a new field, you need to create a named group.
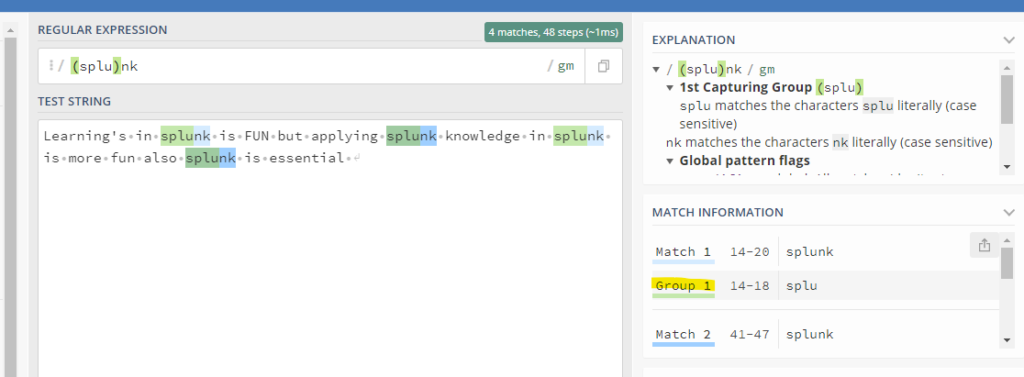
The open and close parenthesis () in a regular expression always matches a group of characters
Here you can observe from the above example , Group 1 is created for the characters which we put in those parenthesis
NAMING THE GROUPS
When the expression is complex and there are too many parenthesis in the expression it becomes difficult to keep the track .In such case you can always capture a group by naming it using the expression ? immediately after opening the parenthesis.

As you can see in the above example abc,pqr and xyz are the groups been created .So we can categorize the above groups in the field called as Name by using the above expression
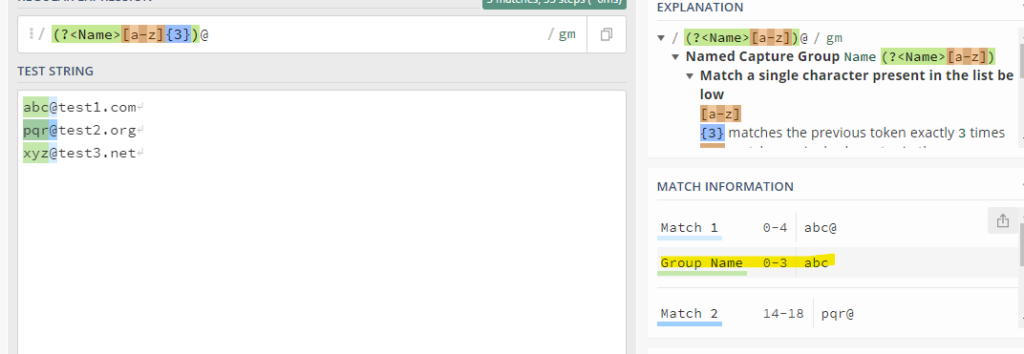
So it can be seen that a group called “Name” field has been created for the paranthesis in which the character are enclosed.
Matching the group
When a regular expression engine encounters a group name it not only creates a group but also sets the group output so that in the later stage of regular expression you can refer it.
It can be referred using the expression (?P=name)
So referring to the fig below,
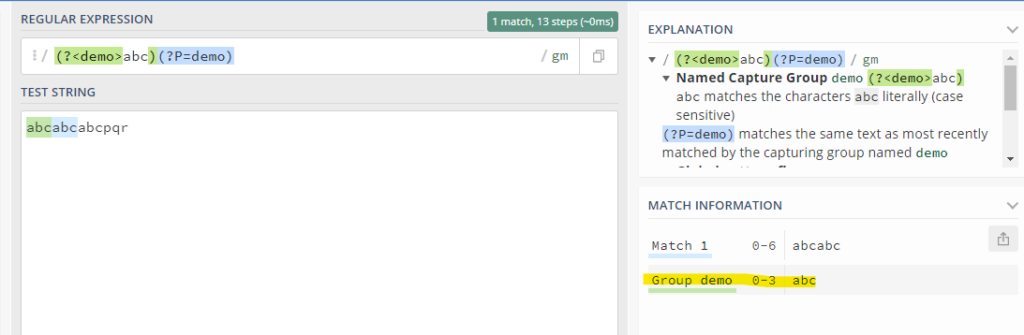
It can be seen that it matches the above demo group created when the match expression is specified.
Recursion
Whenever a regular expression finds a recursive tab, it tries to rerun the regular expression until the entire cycle is completed.
It can be achieved using the expression (?R)
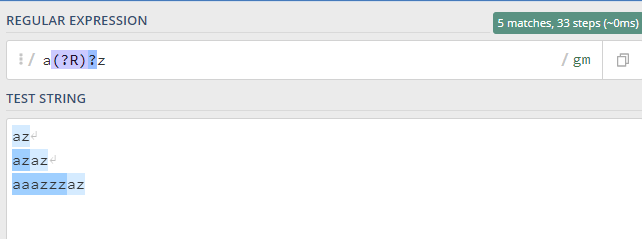
It can be seen that the recurser (?R) matches the character a and z while recursing the entire pattern.
Character Classes in Regular expression
“ [] “ The open and closed square brackets when specified in the regular expression always matches with the characters like alphabets and numbers specified inside the brackets.
- [ab-d ]: It matches one character any of a,b,c ,d
- [^ab-d] : It matches one character except a,b,c,d
- [\b] : It matches the backspace character
- \d : It matches digits which are equivalent to [0-9] in the regular expression
- \D : It matches any character which are not equivalent to a digit
- \s : It’s a space symbol which includes spaces, tabs \t, newlines \n and few other rare characters, such as \v, \f and \r
- \S : It matches any non space white character except \s for an instance of a letter
- \w : It matches any worldly character which are equivalent to [a-z A-Z 0-9_]
- \W : It matches any non worldly character except \w .
4.Assertions in Regular expression
In these you just need to specify the conditions which will assert whether it is true or false
The following are the most commonly used expression for assertions in regular expression
- ^ : It denotes the start of the string
- $ : It specifies the end of the string
- \b : It asserts position at word boundary
- \B : It asserts position where word boundary (\b) does not match
- Lookarounds
It checks whether the character provided in the expression is ahead or behind of the string it provides the match of the test string but does not provide the match of the character specified in the expression
Note : Lookaround expressions matches the given character in the string but they do not consume it
The Lookarounds are classified as below:
(1) Positive lookahead (?=..) : It basically means to look ahead from the current position.

It can be observed above that the match is found when it is specified to match ‘a’ having ‘b’ ahead of it. For simplicity it is checking the condition whether b is ahead of a.
(2) Negative lookahead (?!=..) : It is basically opposite of positive lookahead. It asserts that the character or expression provided does not match the outside string.
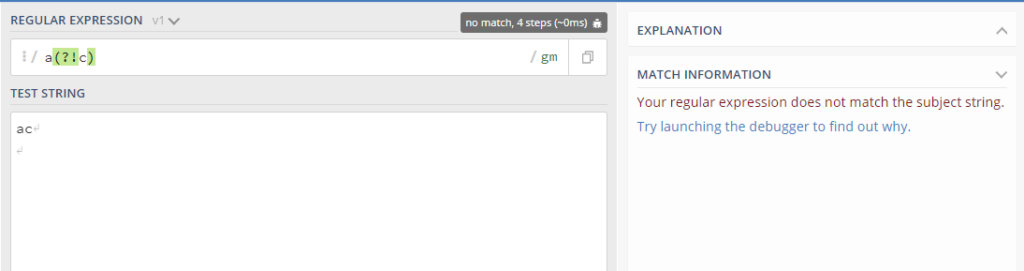
It is basically specifying do not match the expression followed by a, so we are not getting any match when provided with negative lookahead in the example
(4) Positive lookbehind (?<=..) : It indicates to look behind from the current position.Here the regular expression is precedes the string to be matched.
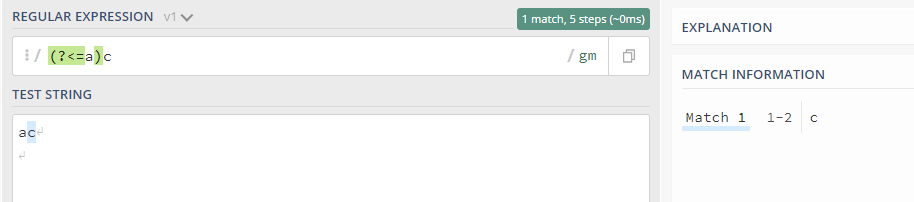
It can be seen that it provides a match character ‘c’ when it is provided to check whether character ‘a’ is behind using positive lookbehind expression.
(5) Negative lookbehind (?<!=..) : It is opposite to that of Positive lookbehind
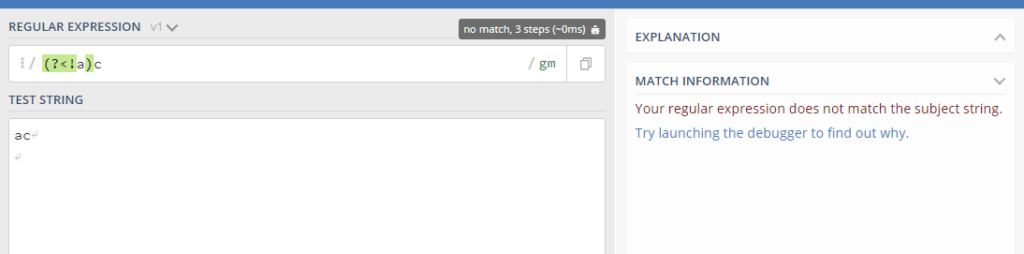
Here we are not provided any match when we specify to look behind the character ‘c’ which does not have character ‘a’ behind it thus making it false.
If you are still facing an issue regarding basic operators of regular expressions, Feel free to Ask Doubts in the Comment Section Below and Don’t Forget to Follow us on 👍 Social Networks. Happy Splunking 😉





{kind=link}